��ƪ��̳�������ؽ�����sql server���ݿ����己�����ݻ��õ����⣬��ϸ������ο����ģ�
������Ҫ˵����һ���ڼ��己�����ݻ��õ�ʱ��������������⣬�����������Ҳ�����ױ���Һ��ԡ�������˵���������������в��ò�ͬ������������ʵ����������ݵ�ʱ������Ҳ������ô˵��һ���Ū�������������ô���¶�����������һ���ҽ������������⡣
��˾����ʹ�õ����ݿ���м������ĺͷ����������ְ汾�����������ר��ʹ�õ�SQLServer�Ƿ������İ�ģ�������Ҫʹ�õ���һ��ʹ�ü������İ�SQLServerר�������ݣ��Ұ���ͨ���������Ѽ������İ�SQLServer�е�һ�����ݱ����뵽����ʹ�õķ������İ�SQLServer�У��ṹ�����ݶ�����ɹ��ˡ���һ��ʼ��û����ʶ������������ʲô���⡣�������ҿ�ʼ����SQL��䣬��ʵ��һ���ܼ�������������ѡ��������£�
select table1.*,table2.*
from table1
inner join table2 on table2.FK = table1.PK
����˵��ô�����û�������ʲô���⣬�����ڲ�ѯ����������ʼ����ʾ���µĴ���
������: ��Ϣ 446������ 16��״̬ 9���� 1
�o������ equal to �����Ķ����nͻ��
����������һ�£�Ȼ���ֿ���һ��T-SQL�İ�������֪��ԭ������Ϊ�ҽ���������SQL Server�е����ݱ����뵽�������ĵ����ݱ��е��Ǻ���ͬԭ���ݵ�����ʽһ�����룬�����˼������ݱ�������ʽ��Ȼ�Ǽ��壬���������бȽϣ��Ӷ�����������İ취��ָ������ʽ�����߲�ѯ������Ӧ���������ɡ��������Ҫ�õ�һ���ؼ��� COLLATE Coliate ��SQLServer�������������������͵�:
COLLATE
һ���Ӿ䣬��Ӧ�������ݿⶨ����ж����Զ����������Ӧ�����ַ�������ʽ��Ӧ���������ͶӰ��
�:
COLLATE < collation_name >
< collation_name > ::=
{ Windows_collation_name } | { SQL_collation_name }
����
collation_name
��Ӧ���ڱ���ʽ���ж�������ݿⶨ��������������ơ�collation_name ����ֻ��ָ���� Windows_collation_name �� SQL_collation_name��
Windows_collation_name
��Windows ������������������ơ���μ�Windows����������ơ�
SQL_collation_name
�� SQL ������������������ơ���μ� SQL ����������ơ�
��ô������ô����֪����ǰ���������������ʲô�أ���ʵ���������������������ڴ������ݿ⣨ʵ������ʱ��Ϳ��Խ���ѡ��ģ�����ͨ����������Ƕ���Ĭ��ԭ�����趨�����������б������������Ǽ������ĵ�SQLServer�ͻ�Ĭ�ϵ�ʹ�ü������ĵ������������Ƿ������ĵ�SQLServer�ͻ�Ĭ�ϵ�ʹ�÷������ĵ�������������ڲ쿴���ݿ⣨ʵ����������ʱ������ҳǩ��������һ�о��ǵ�ǰ�����������Ĭ�ϵ�����£��������ĵ�������������ǣ�Chinese_PRC_CI_AS�����������ĵ���������������ǣ�Chinese_Taiwan_Stroke_CI_AS����������������м��己������������ƻ��õ�ʱ��ֻҪ����һ���㵱ǰҪʹ���������������бȽϾͿ����ˣ��������������Ǹ�SQL��䣬�������ַ��������Խ���Ǹ�������ʾ������
| ����Ϊ���õ����ݣ�
SELECT Table1.*,Table2.* FROM Table1 INNER JOIN Table2 ON Table2.FK = Table1.PK COLLATE Chinese_PRC_CI_AS SELECT Table1.*,Table2.* FROM Table1 INNER JOIN Table2 ON Table2.FK = Table1.PK COLLATE Chinese_Taiwan_Stroke_CI_AS |
˵�˰�����ν����������ͻ��������⣬���������Ȥ�Ļ��������SQL Server����������������������ĸ�������������ҷ���һ�£�ʡ�ô����ȥ�ң�
Microsoft? SQL Server? 2000 ֧�ֶ�����������������Կ�����ȷʹ�����ԣ������������������ĸ��������ŷ����ʹ�õ�������ĸ�� Latin1_General���ַ��Ĺ�����б��롣
ÿ�� SQL Server �������ָ���������ԣ�
���� Unicode �������ͣ�nchar��nvarchar �� ntext���������������������ַ����������У��Լ��ڱȽϲ����ж��ַ�ȡֵ�ķ�����
���ڷ� Unicode �ַ��������ͣ�char��varchar �� text�����������
���ڴ洢�� Unicode �ַ����ݵĴ���ҳ��
˵�� ����ָ���� Unicode �������ͣ�nchar��nvarchar �� ntext����Ӧ�Ĵ���ҳ������ Unicode �ַ���˫�ֽ�λģʽ�� Unicode �������Ҳ��ܸ��ġ�
�����κμ�����ָ�� SQL Server 2000 �������װ SQL Server 2000 ʵ��ʱ����ָ����ʵ����Ĭ���������ÿ�δ������ݿ�ʱ����ָ�����ڸ����ݿ��Ĭ������������δָ������������ݿ��Ĭ�����������ʵ����Ĭ������������ۺ�ʱ�����ַ��С����������������ָ����Щ���������������δָ���������ʹ�����ݿ��Ĭ�����������Щ����
��� SQL Server ʵ���������û���ʹ��ͬһ�����ԣ���Ӧѡ��֧�ָ����Ե�����������磬�������û����������ѡ�����������
��� SQL Server ʵ�����û�ʹ�ö������ԣ���Ӧѡ���ܶԶ����������ṩ���֧�ֵ�����������磬����û�һ�㶼����ŷ���ԣ���ѡ�� Latin1_General �������֧��ʹ�ö������Ե��û�ʱ���������ַ����ݶ�ʹ�� Unicode �������� nchar��nvarchar �� ntext ��Ϊ��Ҫ��Unicode ּ�������� Unicode char��varchar �� text �������͵Ĵ���ҳת�����ѡ���Ϊ������������ڱȽϲ������������� Unicode �ַ����������Ե��� Unicode ��������ʵ�����е���ʱ����������Ի������ͬ����ʹ��ʹ�� Unicode �������ʹ洢�ַ�����ʱ��ҲӦѡ��֧�ִ�����û�����������Է�ʹ�÷� Unicode ��������ʵ���л������
SQL Server ������������ݿ�����洢�Ͳ����ַ��� Unicode ���ݵķ�ʽ��Ȼ��������������Ӧ�ó������Ӧ�ó����н��е��ַ�����ͱȽϽ��ɼ������ѡ���� Windows �������ÿ��ơ�Ӧ�ó���ʹ�õ��ַ���������������� Windows �������ÿ��Ƶ���Ŀ֮һ���������û�����������Ŀ�������֡�ʱ�䡢���ںͻ��Ҹ�ʽ������ Microsoft Windows NT? 4.0��Microsoft Windows? 98 �� Microsoft Windows 95����ʹ�ÿ�������е�"��������"Ӧ�ó���ָ�� Windows �������á����� Microsoft Windows 2000����ʹ��"�������"�е�"����ѡ��"Ӧ�ó���ָ���������á��й� Windows �������õĸ�����Ϣ����μ� Microsoft Web վ�� MSDN? ҳ�е� Developing International Software for Windows 95 and Windows NT 4.0��
����������ɶԷ� Unicode ����ʹ����ͬ�Ĵ���ҳ�����磬����ҳ 1251 ������������ַ����������������� Cyrillic_General��Ukrainian �� Macedonian����ʹ�øô���ҳ����Ȼ��Щ�������ʹ����ͬ��λ������ʾ�� Unicode �ַ����ݣ����ڴ����ֵ䶨��ʱ��Ӧ�õ�����ͱȽϹ������в�ͬ�����ֵ䶨��ȷ�����Ի���ĸ���������������ص���ȷ�ַ����С�
��ΪSQL Server 2000���������� Unicode �ͷ� Unicode ����������Բ���������Ϊ Unicode �ͷ� Unicode ����ָ����ͬ������������������⡣�� SQL Server �����ڰ汾�У��Դ���ҳ�š��ַ��������� Unicode �������ֱ����ָ����SQL Server �����ڰ汾��֧��ÿ������ҳ�в�ͬ��Ŀ���������ΪijЩ����ҳ�ṩ Windows ����������û�е���������� SQL Server 7.0 �У�������ָ��Ϊ�� Unicode ����ѡ������������������� Unicode ���������ᵼ����ʹ����� Unicode ������Ե� Unicode ����ʱ������ͱȽϲ������ز�ͬ�Ľ����
�ؼ��ʱ�ǩ������,����,����,����,
����Ķ�
��������
 SqlServer2005���������ݽ��з������岽��
SqlServer2005���������ݽ��з������岽�� sql serverϵͳ���Ľ������
sql serverϵͳ���Ľ������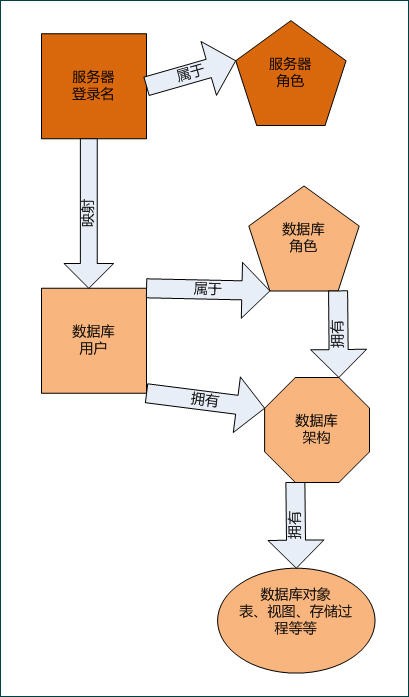 MS-SQL2005��������¼������ɫ�����ݿ��û�
MS-SQL2005��������¼������ɫ�����ݿ��û� Access��SQL Server��Oracle����Ӧ�õ�����
Access��SQL Server��Oracle����Ӧ�õ�����
�������� ���Զ�̱��ݣ���ԭ��SQL2000���ݿ�SQL2000���ݿ�Զ�̵��루�������������ú�ע��ODBC����Դ-odbc����Դ���ý̳�SQL2000��SQL2005���ݿ����˿ڲ鿴����SQL Server 2005������2000����ȷ����������Sql ServerΨһԼ���̳�dz̸JSP JDBC������SQL Server 2005�ķ���SQL Server������������
�鿴����0������>>