以下为引用的内容: set ANSI_NULLS ON
set QUOTED_IDENTIFIER ON
go -- =============================================
-- Author: Arthur Fuller
-- Create date: 23 Aug 2006
-- Description: Table UDF to return Order Totals by Customer
-- Example: SELECT * FROM dbo.CustomerOrderTotals_fnt('VINET')
-- Example: SELECT * FROM dbo.CustomerOrderTotals_fnt(NULL)
-- Notes: This udf is designed to serve two
-- purposes. Pass a CustomerID to limit the rows to
-- that customer, or pass nothing to get all customers
-- =============================================
ALTERFUNCTION [dbo].[CustomerOrderTotals_fnt]
(
-- Add the parameters for the function here
@CustomerID varchar(5)=NULL
)
RETURNS TABLE
AS
RETURN
(
-- Add the SELECT statement with parameter references here
SELECTTOP 100 PERCENT
dbo.Customers.CustomerID,
dbo.Customers.CompanyName,
dbo.Orders.OrderID,
dbo.Orders.OrderDate,
dbo.OrderDetailsSumByOrderID_vue.TotalAmount
FROM
dbo.Customers
INNERJOIN
dbo.Orders ON dbo.Customers.CustomerID = dbo.Orders.CustomerID
INNERJOIN
dbo.OrderDetailsSumByOrderID_vue
ON dbo.Orders.OrderID = dbo.OrderDetailsSumByOrderID_vue.OrderID
WHERE
dbo.Customers.CustomerID = @CustomerID
OR @CustomerID ISNULL
ORDERBY dbo.Orders.OrderDate
) --try it with these:
--SELECT * FROM dbo.CustomerOrderTotals_fnt('VINET')
--SELECT * FROM dbo.CustomerOrderTotals_fnt(NULL)
列表C -- ================================================
-- Template generated from Template Explorer using:
-- Create Inline Function (New Menu).SQL
--
-- Use the Specify Values for Template Parameters
-- command (Ctrl-Shift-M) to fill in the parameter
-- values below.
--
-- This block of comments will not be included in
-- the definition of the function.
-- ================================================
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
-- =============================================
-- Author: Arthur Fuller
-- Create date: 23 Aug 2006
-- Description: Return total sales by Customer
-- Example:
-- SELECT CustomerID, CustomerTotal
-- FROM DBO.CustomerGrandTotal_fnt(null)
-- SELECT CustomerID, CustomerTotal
-- FROM DBO.CustomerGrandTotal_fnt('VINET')
-- SELECT CustomerID, CustomerTotal
-- FROM DBO.CustomerGrandTotal_fnt('VINET')
-- =============================================
CREATEFUNCTION CustomerGrandTotal_fnt
(
@CustomerID varchar(5)
)
RETURNS TABLE
AS
RETURN
(
-- Add the SELECT statement with parameter references 关键词标签:SQL Server 相关阅读
热门文章
![浅谈JSP JDBC来连接SQL Server 2005的方法]() 浅谈JSP JDBC来连接SQL Server 2005的方法
浅谈JSP JDBC来连接SQL Server 2005的方法
 SqlServer2005对现有数据进行分区具体步骤
SqlServer2005对现有数据进行分区具体步骤
 sql server系统表损坏的解决方法
sql server系统表损坏的解决方法
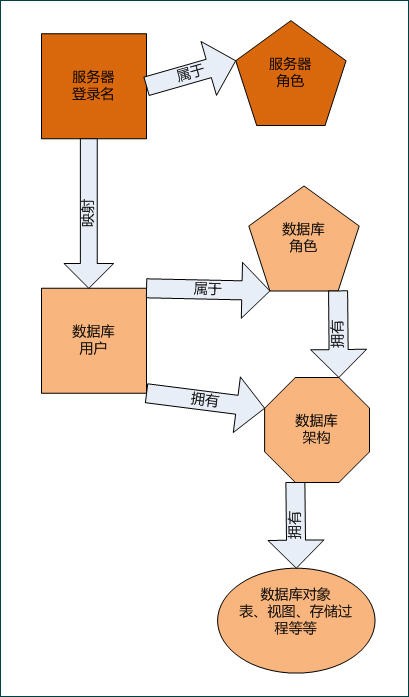 MS-SQL2005服务器登录名、角色、数据库用户、角色、架构的关系
MS-SQL2005服务器登录名、角色、数据库用户、角色、架构的关系 人气排行
配置和注册ODBC数据源-odbc数据源配置教程
如何远程备份(还原)SQL2000数据库
SQL2000数据库远程导入(导出)数据
SQL2000和SQL2005数据库服务端口查看或修改
修改Sql Server唯一约束教程
SQL Server 2005降级到2000的正确操作步骤
sql server系统表损坏的解决方法
浅谈JSP JDBC来连接SQL Server 2005的方法 |
查看所有0条评论>>